|

"Typical big-business historical database has grown a hundredfold in size in the past five years"
|
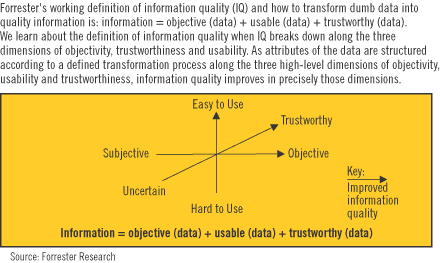
ArticleDATA WAREHOUSING LESSONS LEARNED: TRENDS IN DATA QUALITY Column published in DM Review MagazineBy Lou Agosta Breakdowns in Data and Information Quality Demand Attention The drivers of data and information quality (IQ) often show up as breakdowns - in the accuracy of data, the procedures around data operations and the usability of data. In response, enterprises will make a commitment to managing and improving the quality of data as an enterprise resource. They will advance from defect inspection to a design for information quality by means of a defined methodology leveraging meta data-driven design. In turn, this will drive the development and market penetration of second-generation information quality tools that provide data profiling, standardization, matching, deduplication and integrated meta data. Key Drivers Are Raising Awareness of Data and Information Quality Here are the key forces behind the dynamics that will characterize information quality in 2005: Data defects serious enough to get the attention of the CxO. Thirty percent of data warehousing practitioners who responded to our latest Data Warehousing Institute (TDWI) Forrester Quarterly Technology Survey reported missed deadlines in closing financial books and related statutory reporting due to information and data quality issues, including revenues that were improperly booked or credited due to data quality inaccuracies. The compliance exceptions presented by such data defects have always been serious. From the perspective of Sarbanes-Oxley or other regulatory oversight, they are now showstoppers and must be addressed on a priority basis. Make no mistake - now that data and information quality issues have percolated up to the boardroom, the resources needed to address them will be available. The shiny new CRM system missed the customer. Information quality is the weak underbelly of customer relationship management (CRM) implementations, and this drives the acquisition of information quality solutions. Without information quality, the client implements CRM but misses the 360-degree view of the customer. CRM has brought to the forefront the need to identify individual customers across multiple data sets and the requirement of deduplicating them. Bad data is costly, creating operational inefficiencies. Job failures, rework, lost productivity, redundant data and digital scrap are costly. Mail and packages returned due to incorrect customer contact data are reported by 20 percent of respondents. If the same customer or product data is duplicated multiple times, not only is that information redundant, but so are all the downstream processes that use it - backups, system interfaces and repeated verification of the same data. All are opportunities to reduce the cost of day-to-day operations. Mergers, acquisitions and reorganizations require data integration. Mergers continue apace, and as soon as enterprises formalize the event, the issue of compatibility between their IT systems arises. No reason exists why systems from completely different enterprises should be consistent, aligned or satisfy a unified design. Of course, as a result of the merger, they are now (as a matter of definition) part of a single business enterprise and the result is an information quality breakdown waiting to happen unless the data is inventoried, evaluated and managed proactively as an enterprise asset. For those firms not merging, corporate restructurings and reorganizations surface the need to integrate dysfunctional islands of information and data silos. Loss of trust. A project manager at an insurance company stated, "After trying to reconcile the reports from the ERP system with those from the data warehouse, we knew we couldn't trust the system - the problem is we were not sure which one was wrong." That says it all. Without data and information quality, any system is just shelfware. 2005 Trends to Watch in Information Quality These drivers catalyze the following trends: Data quality will now include meta data quality. Data quality standards and methods will be applied to meta data. By definition, wherever data exists, there is meta data, too. However, all the effort to inspect, clean and standardize data has been applied to plain vanilla data. Meta data quality is scarcely on the radar, and lack of it is a source of data defects in abundance as data modeling and schema integration are misaligned, distributed data stores are not synchronized, and anomalies are allowed to skew data structures and their content. Practitioners will recognize the need to apply rigorous standards to the business rules and related meta data by which data is structured and processed as meta data quality. This will be made the target of explicit codification and impact analysis in the year ahead.
Data profiling will be the first step in information quality improvement. As a result of acquisition and consolidation, the market has validated Forrester's contention that data profiling is not viable as a standalone function but is the first step in the information quality improvement process. Trillium acquired Avellino, a standalone data profiling start-up. Evoke is no longer the last independent data profiling vendor after being acquired by CSI for what was reportedly a fire sale price. Reality is catching up with vendor rhetoric. For years, the mainstream IQ vendors have paid lip service to comprehensive, end-to-end data quality products without supplying them. Such products are now finally coming to market. They integrate data profiling, standardization, reporting (dashboards) and matching by means of end-to-end meta data, which, in turn, enables reuse and impact analysis. In the year ahead, these second-generation IQ tools will be applied to a diversity of data (not just customer), map to methodology-based implementations and provide scorecard-like reporting of key performance indicators. Policy-based information quality leads the way. The design of data is the foundation of information quality success. The structuring of the data through the rigor of data normalization is the groundwork for the subsequent data profiling, standardization and alignment of the meaning of the individual elements as data is produced or captured, operationalized and eventually archived or purged. The policies that define standards for information quality are related to an information quality methodology, which lays down the patterns for practice around raising the capabilities and maturity of the enterprise's relationship to information quality.
Defect inspection gives way to a design for information quality. There is a world of difference between inspecting the content of every individual data element and designing a process that produces the correct output by design. The latter is pursued as part of an integrated methodology for information quality in which data analysis paves the way for data standardization and information quality evaluation and improvement according to a defined, repeatable, measurable process. Significant cost advantages - less work and greater efficiency of operations - accrue to those who are able to certify a process as producing quality results rather than inspecting every item. Thus, data quality standards, processes and tools will advance a level and be applied to meta data quality.
Source: DM Review |
© 2015 IT Dimensions, Inc. All Rights Reserved
If your DQ initiative failed, call us: 1-718-777-3710 | Astoria | New York | USA
|